

Ni los radiólogos ni los modelos de lenguaje multimodales (LLM, por sus siglas en inglés) pueden distinguir fácilmente las imágenes de rayos X “deepfake” generadas por inteligencia artificial (IA) de las auténticas, según un estudio publicado hoy en Radiology, revista de la RSNA. Los hallazgos resaltan los riesgos potenciales asociados con las imágenes de rayos X generadas por IA, así como la necesidad de herramientas y capacitación para proteger la integridad de las imágenes médicas y preparar a los profesionales de la salud para detectar deepfakes.

El término “deepfake” se refiere a un vídeo, fotografía, imagen o grabación de audio que parece real, pero que ha sido creado o manipulado mediante inteligencia artificial.
«Nuestro estudio demuestra que estas radiografías deepfake son lo suficientemente realistas como para engañar a los radiólogos, los especialistas en imágenes médicas más capacitados, incluso cuando sabían que se trataba de imágenes generadas por IA», afirmó el autor principal del estudio, el Dr. Mickael Tordjman, investigador postdoctoral de la Escuela de Medicina Icahn en Mount Sinai, Nueva York.
«Esto crea una vulnerabilidad grave que podría derivar en litigios fraudulentos si, por ejemplo, una fractura fabricada resultara indistinguible de una real. Además, existe un riesgo significativo para la ciberseguridad si los piratas informáticos accedieran a la red de un hospital e inyectaran imágenes sintéticas para manipular los diagnósticos de los pacientes o provocar un caos clínico generalizado al socavar la fiabilidad fundamental del historial clínico digital».
Diecisiete radiólogos de doce centros diferentes en seis países (Estados Unidos, Francia, Alemania, Turquía, Reino Unido y Emiratos Árabes Unidos) participaron en el estudio retrospectivo. Su experiencia profesional oscilaba entre 0 y 40 años. La mitad de las 264 imágenes de rayos X del estudio eran auténticas, y la otra mitad fueron generadas por IA. Los radiólogos fueron evaluados en dos conjuntos de imágenes distintos, sin superposición entre ellos. El primer conjunto de datos incluía imágenes reales y generadas por ChatGPT de múltiples regiones anatómicas. El segundo conjunto de datos incluía imágenes de rayos X de tórax: la mitad auténticas y la otra mitad creadas por RoentGen, un modelo de difusión de IA generativa de código abierto desarrollado por investigadores de Stanford Medicine.
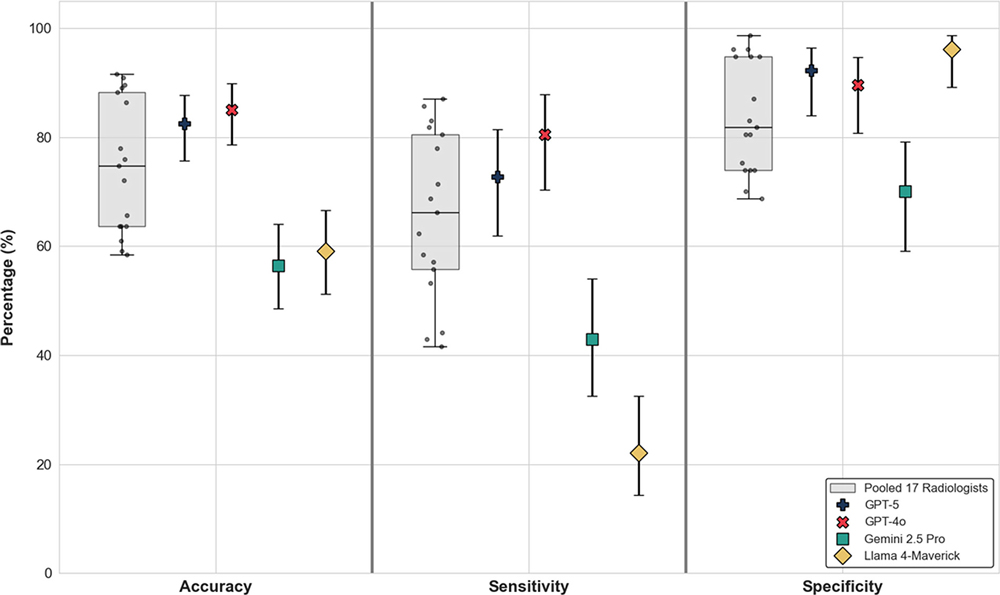
Cuando los radiólogos desconocían el verdadero propósito del estudio, pero se les preguntó, tras evaluar la calidad técnica de cada imagen de ChatGPT, si habían notado algo inusual, solo el 41 % identificó espontáneamente las imágenes generadas por IA. Tras ser informados de que el conjunto de datos contenía imágenes sintéticas, la precisión media de los radiólogos para diferenciar las radiografías reales de las sintéticas fue del 75 %.
El rendimiento de cada radiólogo en la detección precisa de las imágenes generadas por ChatGPT osciló entre el 58 % y el 92 %. De manera similar, la precisión de cuatro modelos de aprendizaje automático multimodales (GPT-4o, GPT-5, Gemini 2.5 Pro, Google y Llama 4 Maverick, Meta) varió entre el 57 % y el 85 %. Incluso ChatGPT-4o, el modelo utilizado para crear los deepfakes, no pudo detectarlos todos con precisión, aunque identificó la mayoría con una diferencia considerable en comparación con los modelos de Google y Meta.
La precisión de los radiólogos en la detección de las radiografías de tórax sintéticas de RoentGen osciló entre el 62 % y el 78 %, y el rendimiento de los modelos LLM osciló entre el 52 % y el 89 %.
No se encontró correlación entre los años de experiencia de un radiólogo y su precisión en la detección de imágenes de rayos X sintéticas. Sin embargo, los radiólogos musculoesqueléticos demostraron una precisión significativamente mayor que otros subespecialistas en radiología.
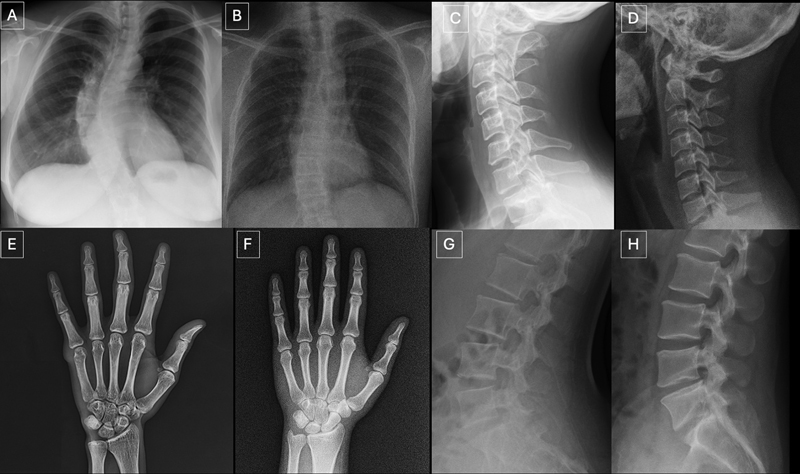
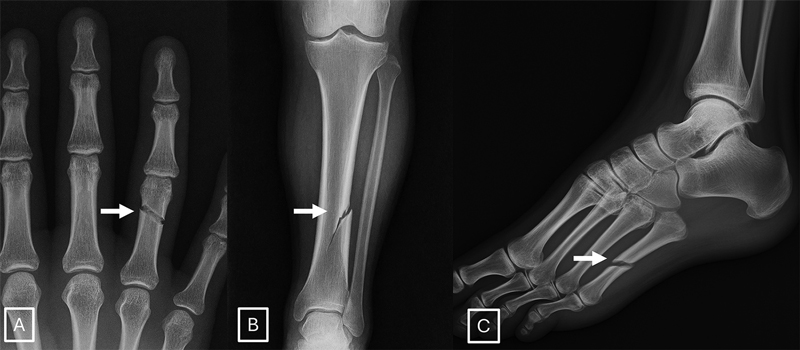
El estudio identificó características comunes de los rayos X sintéticos.
«Las imágenes médicas generadas mediante deepfake suelen parecer demasiado perfectas», afirmó el Dr. Tordjman. «Los huesos son excesivamente lisos, las columnas vertebrales anormalmente rectas, los pulmones excesivamente simétricos, los patrones de los vasos sanguíneos excesivamente uniformes y las fracturas aparecen inusualmente limpias y consistentes, a menudo limitadas a un solo lado del hueso».
Entre las soluciones recomendadas para distinguir claramente las imágenes reales de las falsas y ayudar a prevenir la manipulación se incluyen la implementación de medidas de seguridad digitales avanzadas, como marcas de agua invisibles que incorporan datos de propiedad o identidad directamente en las imágenes y la adición automática de firmas criptográficas vinculadas a un tecnólogo cuando se capturan las imágenes.
«Posiblemente solo estemos viendo la punta del iceberg», afirmó el Dr. Tordjman. «El siguiente paso lógico en esta evolución es la generación de imágenes 3D sintéticas mediante IA, como las obtenidas mediante tomografía computarizada (TC) y resonancia magnética (RM). Es fundamental establecer ahora conjuntos de datos educativos y herramientas de detección».
Los autores del estudio han publicado un conjunto de datos deepfake seleccionados, con cuestionarios interactivos, con fines educativos.